Usman AnwarI am a final year PhD student in Computational and Biological Learning lab at Cambridge University, UK. I am broadly interested in AI Safety and Alignment, with my recent focus on chain-of-thought monitorability. I am supervised by David Kruger and funded by Open Phil AI Fellowship and Vitalik Buterin Fellowship on AI Safety. Email / GitHub / Google Scholar / LinkedIn / CV If you want to chat or collaborate with me, or pitch me on what I should do post-PhD, please drop me an email. |

|
Selected Publications
|
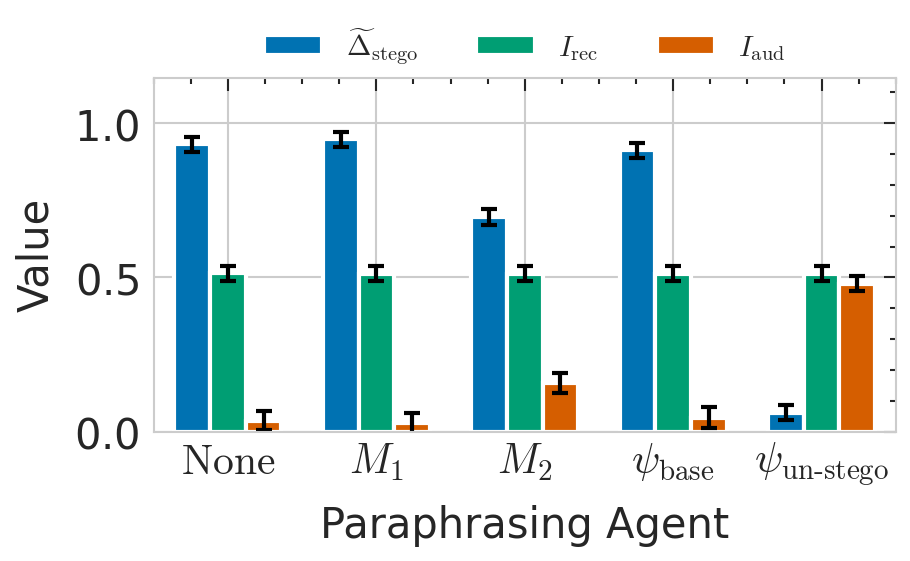
A Decision-Theoretic Formalisation of Steganography With Applications to LLM MonitoringUsman Anwar*, Julianna Piskorz*, David D. Baek, David Africa, Jim Weatherall, Max Tegmark, Christian Schroeder de Witt, Mihaela van der Schaar, David Krueger Under review, 2026 arxiv / Current approaches to detecting hidden communication in AI systems rely on ad-hoc approaches such as inspecting messages for anomalies. We introduce a new framework that instead detects steganography through its behavioral effects; measuring whether a signal helps intended recipients more than outside monitors on real tasks. |
|
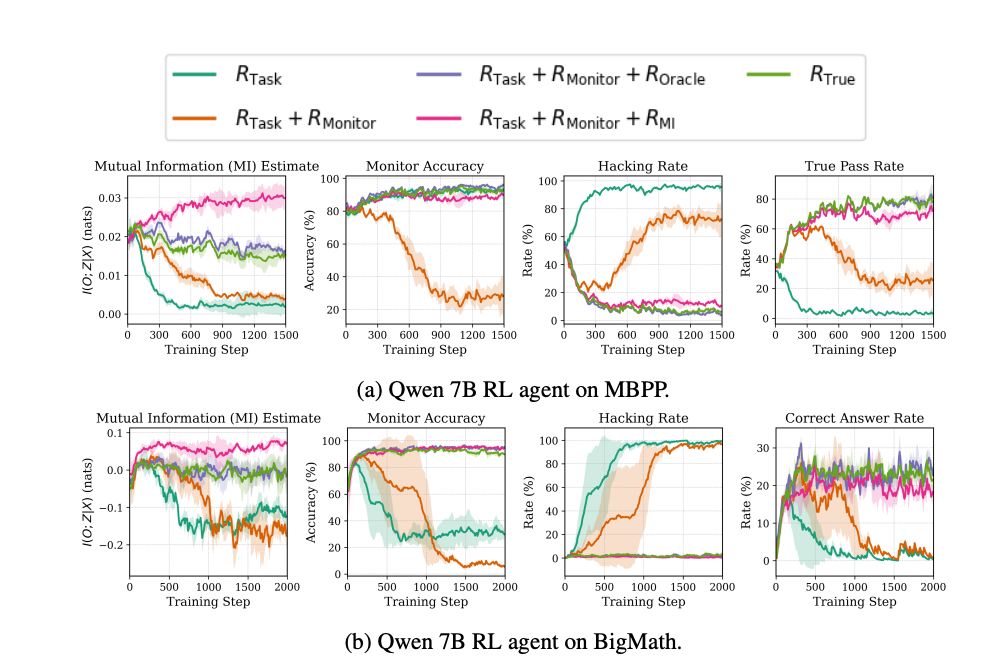
Analyzing and Improving Chain-of-Thought Monitorability Through Information TheoryUsman Anwar*, Tim Baker*, Dana Kianfar, Cristina Pinneri, Christos Louizos Under review, 2026 arxiv / tweetprint / pdf / We propose a simple training objective based on mutual information that prevents CoT obfuscation and maintains CoT monitorability when models are optimized against monitors. Through our theoretical analysis, we also characterize two possible failure modes for practical monitors: information gap, where the monitor cannot interpret the model’s reasoning, and elicitation error, where the monitor fails to correctly evaluate outputs for the target attribute. |

|
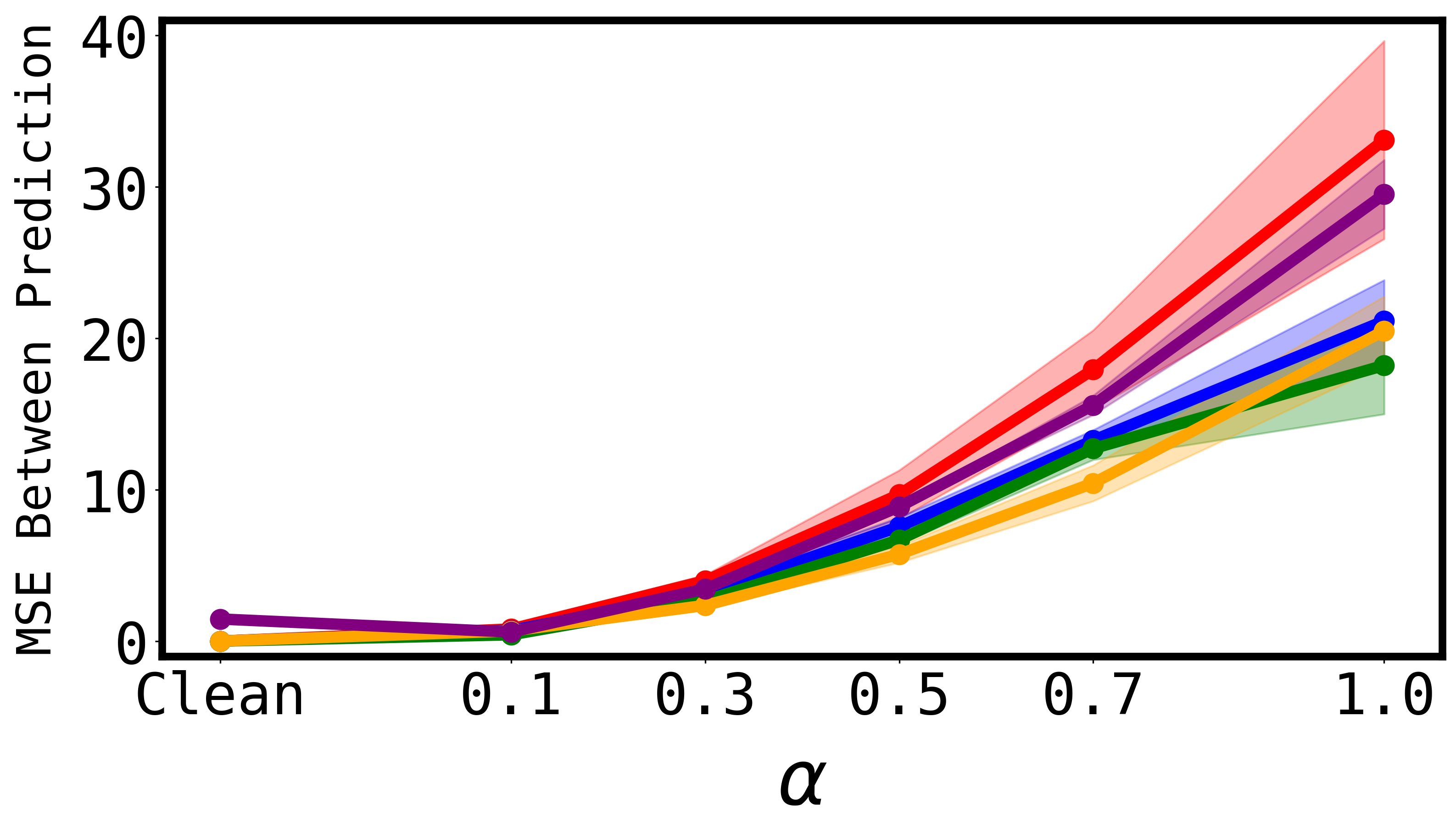
Interpreting Emergent Planning in Model-Free Reinforcement LearningUsman Anwar*, Thomas Bush*, Stephen Chung, Adria Garriga-Alonso, David Krueger International Conference on Learning Representations (ICLR 2025), Oral, 2025 arxiv / tweetprint / We provide the first mechanistic evidence that standard model-free RL agents can perform planning by using implicitly learned world-models. |
|
Understanding In-Context Learning of Linear Models in Transformers Through an Adversarial LensUsman Anwar, Johannes Von Oswald, Louis Kirsch, David Krueger, Spencer Frei Transactions on Machine Learning Research (Featured Certification, 2025), 2025 arxiv / tweetprint / We show that transformers do not learn adversarially robust in-context learning algorithms for linear regression and that these learned algorithms do not correspond to classical algorithms for linear regression. We also provide evidence of non-universality in terms of algorithms learned by identical tranformers. |
|
Foundational Challenges in Assuring Alignment and Safety of Large Language ModelsUsman Anwar and 41 other authors Transactions on Machine Learning Research (Survey Certification), 2024 arxiv / tweetprint / This 150+ pages long agenda identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose 200+, concrete research questions. |
|
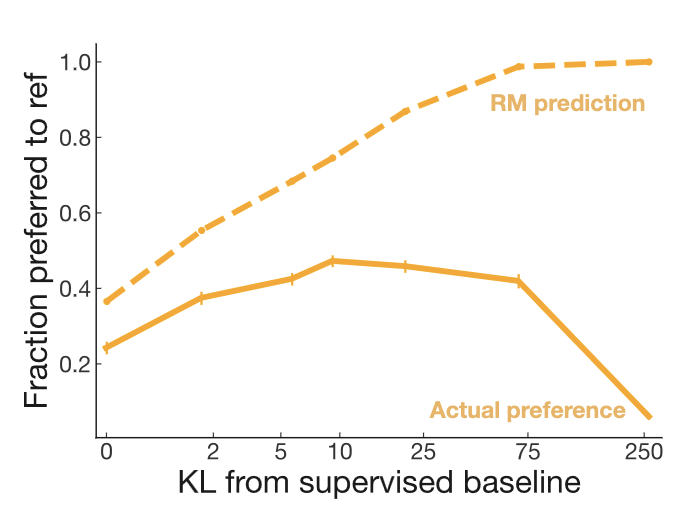
Reward Model Ensembles Help Mitigate OveroptimizationThomas Coste, Usman Anwar, Robert Kirk, David Krueger Internation Conference on Learning Representations, 2024 arxiv / code / We show that using an ensmeble of reward models can be effective in mitigating overoptimization. |
|
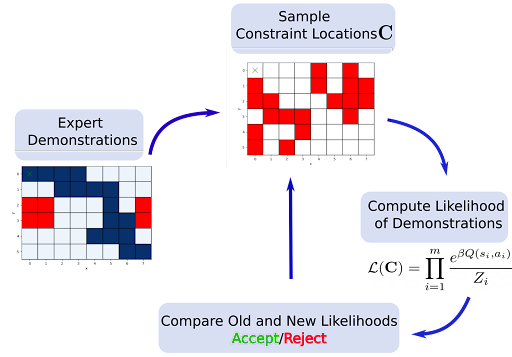
Bayesian Methods for Constraint Inference in Reinforcement LearningDimitris Papadimitriou, Usman Anwar, Daniel Brown Transactions on Machine Learning Research, 2022 paper / poster / We develop a Bayesian approach for learning constraints which provides several advantages as it can work with partial trajectories, is applicable in both stochastic and deterministic environments and due to its ability to provide a posterior distribution enables use of active learning for accurate learning of constraints. |

|
Inverse Constrained Reinforcement LearningUsman Anwar*, Shehryar Malik*, Alireza Aghasi, Ali Ahmed Internation Conference on Machine Learning, 2021 arxiv / video / code / poster / slides / We propose a framework for learning Markovian constraints from user demonstrations in high dimensional, continuous settings. We empirically show that constraints thus learned are general and transfer well to agents with different dynamics and morphologies. |
{kind=link}
|
Design and source code from Leonid Keselman's website |